Real-Time Shopping Recommendations in 150ms: Building a Modern E-Commerce Discovery Engine
How we built a production-grade product recommendation system that turns natural language into personalized product bundles faster than you can blink.

Traditional e-commerce search is broken. Customers type “couch” and get 10,000 results sorted by price. They want a complete living room but have to manually match styles, check budgets, and hope everything arrives in matching colors.
In today’s AI-first world, this experience is unacceptable.
Our goal: Design a system that turns natural language prompts into personalized product bundles in 150ms or less while:
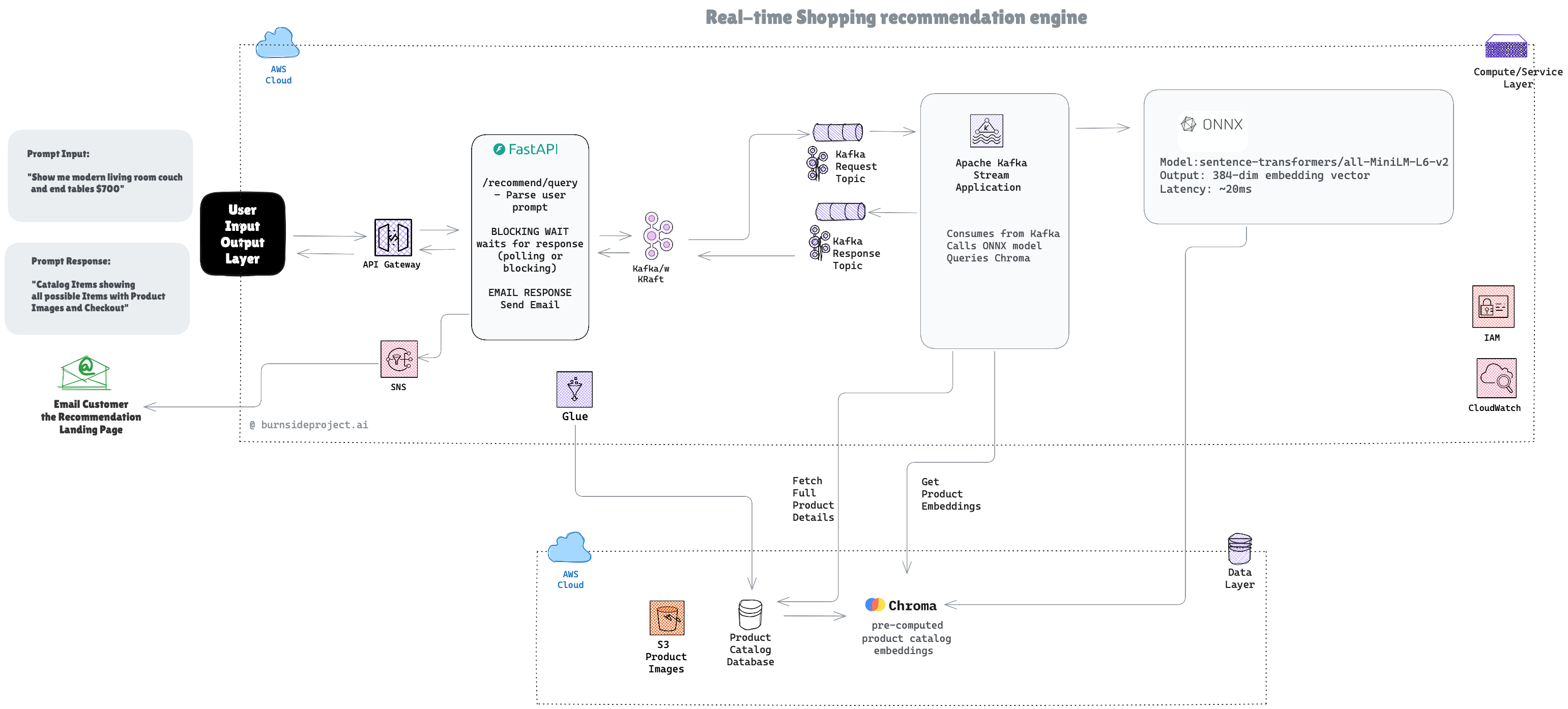
We selected all-MiniLM-L6-v2, an open-source Sentence-Transformer model from Hugging Face, to power our product-catalog embeddings. It strikes the ideal balance between speed and semantic accuracy, generating dense vector representations that capture product meaning rather than just keywords. Exported to ONNX, it runs natively in our Java inference stack, giving us lightweight, low-latency embeddings without Python dependencies — perfect for real-time recommendations at scale.
After extensive iteration and refinement, we landed on a hybrid batch + real-time pipeline that leverages Apache Kafka Streams, ONNX ML inference, and vector databases to deliver sub-150ms personalized recommendations.
When a customer types a prompt:
Key Decision: Parse natural language synchronously (5ms) but process asynchronously. Don’t make the customer wait for ML inference.
Response time: 5ms to acknowledge
Apache Kafka Streams consumes from Kafka and orchestrates the ML pipeline:
Key Decision: Embedding generation happens in real-time (not pre-computed) because user queries are unpredictable. Product embeddings are pre-computed daily.
Processing time: 100-125ms typical, 200ms worst-case
We use two databases for different purposes:
Purpose: Fast similarity search (30ms for 300 products)
Query: “Find products semantically similar to this embedding”
Returns: List of SKUs with similarity scores
E-commerce recommendations don’t have regulatory retention (unlike credit cards), but we store for business intelligence:
Cost per recommendation: $0.00001 (negligible)
We added Redis caching in month 3 after PostgreSQL became a bottleneck. Wish we’d done it from the start.
Impact: 10x faster product fetches, 99% cache hit rate, $50/month cost.
We built the recommendation engine but didn’t have infrastructure to test algorithm improvements.
Fix: Add feature flags (LaunchDarkly) to test:
We self-hosted Kafka to save money. Reality: Operational burden wasn’t worth the $200/month savings.
Fix: Migrate to AWS MSK. Less toil, better monitoring, automatic upgrades.
We monitored P99 latency religiously but didn’t track:
Fix: Emit business events to Kafka and build real-time dashboards.
Total AWS services: 12
Open source components: 4 (Kafka, Kafka Streams, ONNX, Chroma)
By combining vector databases, real-time ML inference, and event-driven processing, we transformed keyword search into an AI-powered shopping assistant.
A system that:
Modern shopping recommendations don’t have to be slow or expensive. With the right architecture, they take 150ms.
This architecture is based on real-world production systems at e-commerce companies. If you’re building similar real-time recommendation systems, I’d love to hear about your experiences.
What challenges have you faced with semantic search and ML inference? Drop a comment below!
What challenges have you faced with real-time processing? Drop a comment below!
Connect:LinkedIn
Company: Burnside Project
Website: burnsideproject.ai
Written by AI Engineering
Senior engineer with expertise in machine learning. Passionate about building scalable systems and sharing knowledge with the engineering community.
Related Articles
Continue reading about machine learning

The Silent Cold Start Problem in Predictive Engines
Every ML-powered monitoring tool faces the same uncomfortable question on day one: How do you predict failures you’ve never seen?

PostgreSQL HA in 2 Hours: How AI Agents Are Changing the game
The Ask: Production-grade HA without a DBA on payroll
Stay Ahead of the Curve
Get weekly notes on PostgreSQL products and AI-agent consulting
Join engineers evaluating open PostgreSQL workflows