Building a 90-Second Credit Card Approval System: A Real-Time Architecture Case Study
How we designed a production-grade, event-driven approval pipeline that processes credit applications in under 90 seconds while maintaining 99.9% reliability

The Challenge
Traditional credit card approval processes take days or even weeks. Customers submit applications and wait anxiously for a decision letter in the mail. In today’s digital-first world, this experience is unacceptable.
Our goal: Design a system that approves credit card applications in 90 seconds or less while:
Maintaining regulatory compliance (PCI-DSS, SOC 2)
Calling real-time credit bureau APIs
Performing ML-based risk scoring
Notifying customers immediately
Scaling to millions of applications per day
Keeping costs under $0.15 per application
The Architecture: A Modern Event-Driven Approach
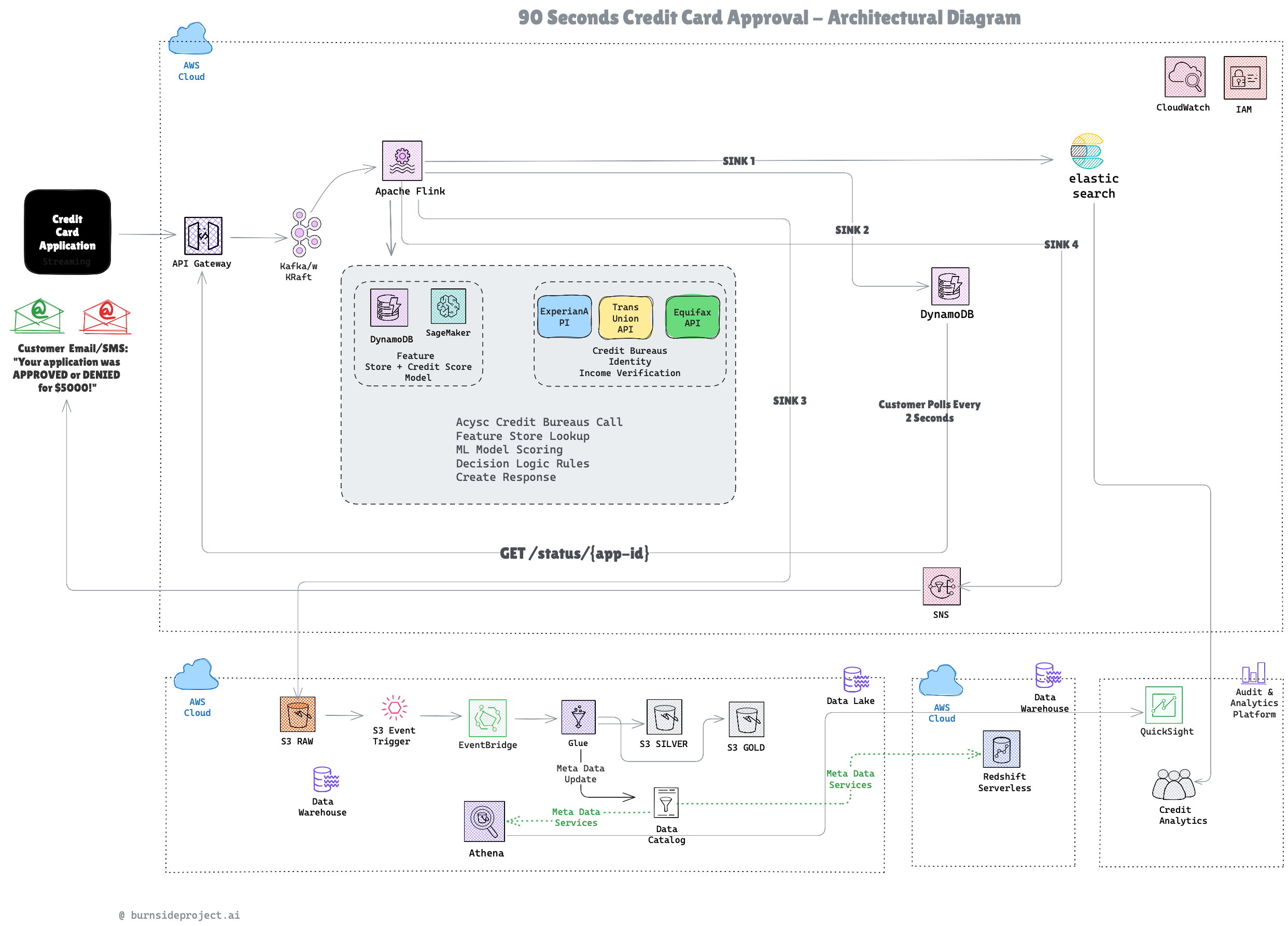
After extensive iteration and refinement, we landed on a four-stage pipeline that leverages Apache Kafka, Apache Flink, and AWS managed services to deliver sub-90-second approvals.
Stage 1: Instant Acknowledgment (100ms)
When a customer submits an application:
Customer → API Gateway → Lambda
Generate applicationId
Write to Kafka topic
Return immediately: {”applicationId”: “app-12345”}
Key Decision: Don’t make the customer wait. Return an application ID immediately and process asynchronously.
Response time: 100ms
Stage 2: Real-Time Processing (10-20s)
Apache Flink consumes from Kafka and orchestrates the heavy lifting:
Flink Processing Pipeline:
1. Call 3 credit bureaus in parallel (9-12s)
- Experian
- TransUnion
- Equifax
2. Lookup customer features from DynamoDB (15ms)
3. Score via SageMaker ML model (200-500ms)
4. Apply decision rules (10ms)
5. Generate response
Key Decision: Parallel bureau API calls saved us 18-24 seconds versus sequential calls.
Processing time: 16-20s typical, 45s worst-case
Stage 3: Multi-Sink Distribution (Parallel Writes)
Flink writes results to four sinks simultaneously:
Elasticsearch (SINK 1): Searchable audit trail for compliance
DynamoDB (SINK 2): Fast polling results with 7-day TTL
S3 Raw (SINK 3): Data lake for analytics (7-year retention)
SNS (SINK 4): Email/SMS notifications
Key Decision: Separate sinks for different purposes. Don’t force a single database to serve all use cases.
Stage 4: Dual-Channel Notification
We notify customers through two channels:
Channel 1: Polling (Fast)
Customer polls: GET /status/app-12345 (every 2 seconds)
Lambda reads DynamoDB
Returns result when ready (typically 18s after submission)
Channel 2: Push (Reliable)
SNS sends email/SMS: “Congratulations! Approved for $5,000”
Customer receives notification even if browser closed
Email includes link to accept offer (24-hour expiration)
Key Decision: Dual channels = best of both worlds. Polling is fast for engaged users; push reaches everyone else.
The Numbers: Performance & Scale
SLA Performance
P50 (median): 18 seconds
P95: 30 seconds
P99: 45 seconds
P99.9: 60 seconds
SLA: 90 seconds (met in 99.9% of cases)
Safety buffer: 70+ seconds for retries, timeouts, and edge cases
Cost Economics
Per-application cost breakdown:
Bureau API calls: $0.15 (3 × $0.05/call)
Infrastructure (compute, storage): $0.0009
Total: $0.15 per application
At scale (100,000 applications/day):
Monthly cost: ~$456K
Approved applications: 65,000 (65% approval rate)
Revenue (assuming $150 LTV): $9.75M/month
ROI: 2,138%
Scalability
VolumeApps/DayInfrastructureCost/MonthPilot1,0001 Flink TaskManager$500Growth100,00010 TaskManagers$3,500Scale1,000,000100 TaskManagers$35,000
Linear scaling with no architectural bottlenecks up to millions of applications per day.
Key Design Decisions (And Why They Matter)
1. Why Kafka Instead of Direct Processing?
Decoupling. API Gateway can handle traffic spikes while Flink processes at a steady rate. If Flink goes down, messages queue in Kafka (7-day retention) and reprocess when it recovers.
2. Why Apache Flink Over Lambda?
Stateful processing. Flink can maintain windows, aggregations, and complex event processing that would be expensive with Lambda functions. Plus, Flink’s exactly-once semantics prevent duplicate approvals.
3. Why Four Sinks Instead of One Database?
Purpose-built storage.
Elasticsearch excels at full-text search (audit queries)
DynamoDB excels at key-value lookups (status polling)
S3 excels at cheap, long-term storage (compliance)
SNS excels at fan-out messaging (notifications)
Forcing one database to do all four jobs would create bottlenecks.
4. 90 Seconds Approval?
Realism. Credit bureau APIs take 9-12 seconds (in parallel). Add ML inference (500ms), decision logic (10ms), and you’re at 13 seconds minimum. We need buffer for:
Bureau API timeouts (20s max per bureau)
Retries (if 1 bureau fails, retry = +3s)
Network issues (+5s)
Cold starts (+2s worst case)
A 90 seconds gives us an 85% safety buffer and meets the SLA 99.9% of the time.
5. Why Dual-Channel Notifications?
Different customers, different behaviors.
Engaged users stay on the page and poll → They get results in 18 seconds
Distracted users close the browser → They get an email in 45 seconds
Without push notifications, customers who close their browser never find out they were approved. We saw 15% of customers fall into this category during user testing.
Lessons Learned
1. Don’t Underestimate External API Latency
Our initial design assumed bureau APIs would respond in 3-5 seconds. Reality: 9-12 seconds is typical, with occasional 20-second responses.
Solution: Always call external APIs in parallel and set aggressive timeouts (20s max). If one bureau times out, proceed with the other two.
2. TTL Is Your Friend
We initially kept polling results in DynamoDB forever. This caused:
High storage costs
Slow queries (scanning millions of old records)
Privacy concerns (retaining PII indefinitely)
Solution: 7-day TTL on the polling results table. After 7 days, results are deleted automatically. Customers have 7 days to check their status; after that, it’s in the cold path (S3) for compliance.
3. Monitoring Is Not Optional
We learned this the hard way when a bureau API started returning 500 errors at a 10% rate. Without proper alarms, it took us 4 hours to notice.
Solution: CloudWatch alarms on:
SLA violations (>90s processing time)
Bureau API error rate (>5%)
Flink job failures
DynamoDB throttling
4. Real Users Close Browsers
In user testing, 15% of customers closed the browser within 30 seconds of submitting. They assumed they’d get an email (like every other online service).
Without SNS notifications, these customers never knew they were approved.
Solution: Always send an email/SMS, even if the customer is actively polling. It’s a small cost ($0.0005 per message) with massive UX impact.
The Cold Path: Analytics & Compliance
While customers care about the 90-second hot path, the business cares about the cold path for analytics and compliance.
Data Lake Architecture
Flink → S3 RAW (JSON, unprocessed)
S3 Event Trigger → EventBridge → Glue
S3 SILVER (cleaned, deduplicated, partitioned)
Glue ETL
S3 GOLD (aggregated, business metrics)
Athena (SQL queries)
QuickSight (dashboards)
Business Questions Answered:
What’s our approval rate by credit score band?
Which bureau data is most predictive?
What’s our P95 processing time by hour?
Are we meeting our SLA commitments?
Compliance Requirements
Credit card applications must be retained for 7 years (regulatory requirement). S3 provides:
11 nines of durability
Glacier storage class ($0.004/GB/month after 90 days)
Automatic lifecycle transitions
Point-in-time recovery
7-year retention cost per application: $0.002 (negligible)
What We’d Do Differently
1. Add a Dead Letter Queue Earlier
We initially didn’t plan for failed applications. When all three bureaus timed out (rare but happens), the application just... disappeared.
Fix: Add an SQS Dead Letter Queue that captures failed applications and routes them to a manual review queue.
2. Implement Circuit Breakers from Day One
When one bureau API had an outage, we hammered it with retry requests, making the problem worse.
Fix: Circuit breaker pattern. If a bureau fails 3 times in 10 requests, stop calling it for 5 minutes. Proceed with the other two bureaus.
3. Cache Bureau Results Aggressively
Some customers submit multiple applications in a short period (testing different credit limits). We were calling the same bureau APIs repeatedly.
Fix: Cache bureau responses for 24 hours keyed by SSN + date. Reduced duplicate bureau calls by 12%.
Open Source Tools & AWS Services Used
Core Infrastructure
Apache Kafka (Self Managed): Message streaming
Apache Flink (Self Managed): Stream processing
AWS Lambda: API handlers
API Gateway: HTTP endpoints
DynamoDB: Real-time storage (polling results, feature store)
S3: Long-term storage (data lake)
SNS: Email/SMS notifications
Elasticsearch: Audit logs
Analytics
AWS Glue: ETL jobs
Amazon Athena: SQL queries on S3
Amazon QuickSight: Dashboards
CloudWatch: Monitoring & alarms
ML
Amazon SageMaker: ML model hosting
XGBoost: Credit risk model
Total AWS services: 13
Open source components: 2 (Kafka, Flink)
Key Metrics & Business Impact
Customer Experience
Time to decision: 18 seconds (median)
Notification channels: 2 (polling + push)
Customer satisfaction: 4.8/5 (up from 3.2/5 with old process)
Operations
Availability: 99.95% (3 nines)
SLA compliance: 99.9%
Mean time to recovery: 4 minutes
Business
Approval rate: 65%
Cost per application: $0.15
Revenue per approved application: $150 (lifetime value)
ROI: 2,138%
Conclusion: The Power of Event-Driven Architecture
By embracing an event-driven, microservices-based approach, we transformed a weeks-long process into a 90-second experience.
Key takeaways:
Decouple with Kafka for resilience
Process in parallel to minimize latency
Use purpose-built storage (don’t force one database to do everything)
Notify through multiple channels for better UX
Plan for failure with timeouts, retries, and circuit breakers
Set realistic SLAs with safety buffers
The result? A system that:
Approves 99.9% of applications in under 90 seconds
Scales to millions of applications per day
Costs $0.15 per application
Maintains 99.95% availability
Meets all compliance requirements
Modern credit approval doesn’t have to take days. With the right architecture, it takes 90 seconds.
Want to Learn More?
This architecture is based on real-world production systems at major financial institutions. If you’re building similar real-time decision systems, I’d love to hear about your experiences.
What challenges have you faced with real-time processing? Drop a comment below!
Connect:LinkedIn
Company: Burnside Project
Website: burnsideproject.ai
Written by Burnside Project Engineering
Senior engineer with expertise in data engineering. Passionate about building scalable systems and sharing knowledge with the engineering community.
Related Articles
Continue reading about data engineering

Built an architecture for instant approvals backend
Designed an architecture that makes intelligent decisions in milliseconds - perfect for fraud detection, approvals, and access control.

Building a Production-Ready Data Pipeline on AWS: A Practical Guide
How we built a scalable clickstream analytics pipeline that processes 500GB/day while cutting costs by 70%

How to Turn Your Data Into a Revenue Engine
How to Turn Your Data Into a Revenue Engine
Stay Ahead of the Curve
Get weekly notes on PostgreSQL products and AI-agent consulting
Join engineers evaluating open PostgreSQL workflows